多串的 SAM
广义SAM
SAM 是我们处理字符串问题最有效的工具之一,但它和很多工具一样有一个问题,那就是无法处理主串有多个的情况,于是我们就有了广义的 SAM
约定
模式串为 $s_1, s_2, … s_n$ ,其长度和为 $m$
将模式串建出的 Trie 为 $T$ ,其中节点个数为 $\mid T \mid$
$G(T)$ 表示 Trie 树中所有叶节点的深度和
不难证明,如果给定模式串集去构建 Trie ,则 $G(T) = O(m) = O(\mid T \mid)$ ;但如果直接给定一个 Tire , $G(T) = \mid T \mid^2$
- $A$ 为字符集
假广义 SAM
首先,网上流传着许多假的广义 SAM 写法,虽然它们是假的,但既然流传出来,说明还是有一定优势,那就是好打 + 好想(估计后者占主要),这里介绍几种:
把多个串用特殊符号连起来,然后再建 SAM
优点是好想;缺点是你要加一些特判处理掉特殊符号,而且时间复杂度是 $O(m)$ 且常数好像很大(我没试过,但都说它危险)
每次插入一个串时把 $last$ 设为 $1$ ,再像普通 SAM 一样插入
优点是好打(改两下就完了),且大部分时候可以保证正确性(比如 luogu 的板子题);但缺点是会出现一些多余节点,有时候它们会影响答案,另外,时间是 $O(m)$ 但比 $1$ 快
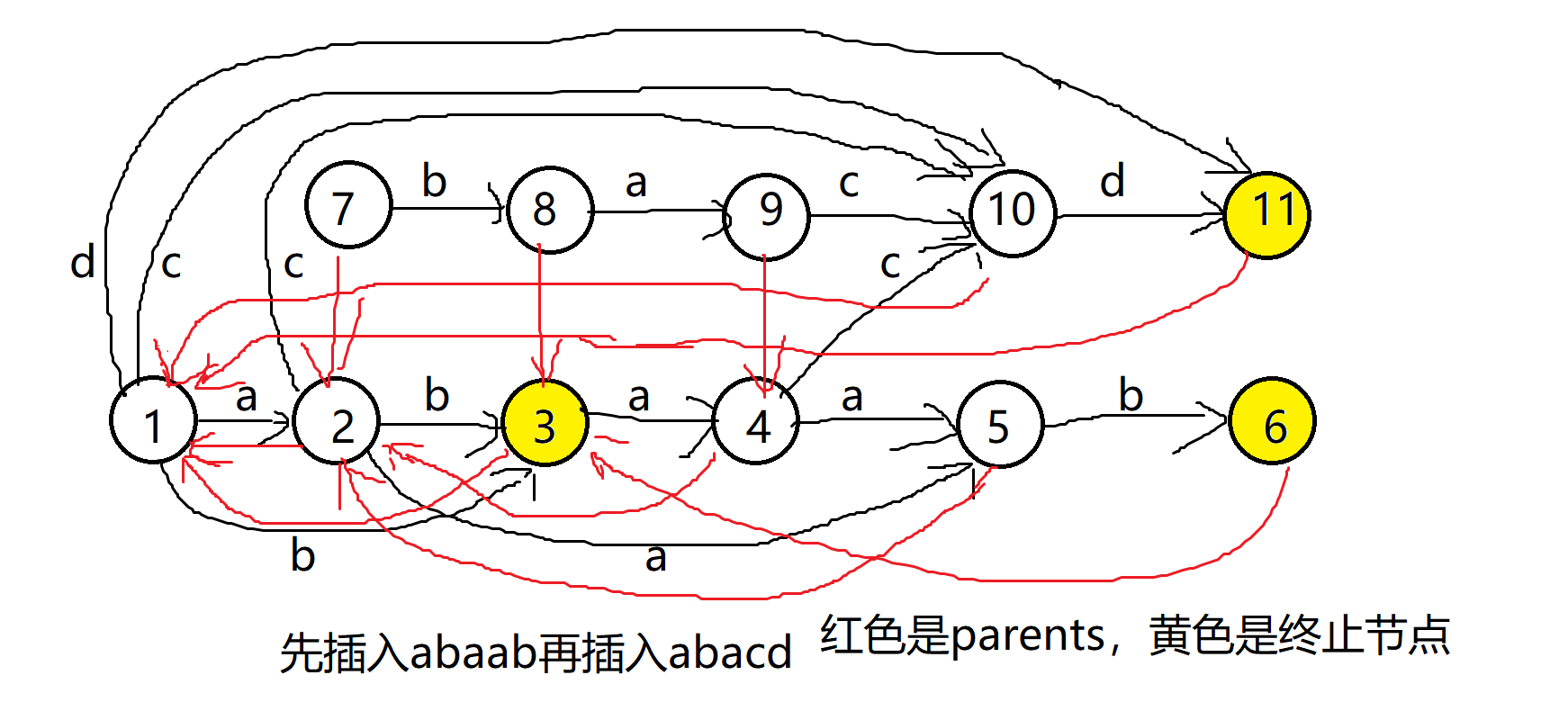 (如图, $7, 8, 9$ 号节点是多余的)
(如图, $7, 8, 9$ 号节点是多余的)
其它还有一些,这里就不介绍了
离线版
我们都知道, SAM 的构造是在线的,这也是它的一个优势;而广义 SAM 也可以在线构造,不过在此之前,我们先学习离线构造方法
发现假广义 SAM $2$ 只是多了几个点,而多点的原因是 $aba$ 这个串被重复插入了,那么我们不妨先在一棵上 Trie 树把所有串插入,那么 Tire 树自然就帮我们合并了重复的部分,然后在 Tire 树上 dfs ,每次插入字符 $x$ 时,把 $last$ 设为 Trie 树上它的父节点对应 SAM 中节点即可,这其实就很像是假 SAM $2$ 的优化;发现 dfs 的时间是 $O(G(T))$ (因为你插入一个节点,它可能比前面的节点深度小,那你就要跳 parents 去修改)在出题人直接给出 Trie 树的时候时间为 $O(\mid T \mid^2)$ 很劣,我们把 dfs 换成 bfs ,时间保证为 $O(\mid T \mid) = O(m)$ ,而且在给定的串没有 lcp (也就是 Trie 建了个寂寞)的时候, bfs 写法可以避免很多特判
给出板子:
1 |
|
在线版
在线是 SAM 的一大优势,那如何把这个优势传承到广义 SAM 呢?
显然,我们建 Trie 的目的是压缩 lcp ,找到 last ,依次弥补假 SAM $2$ 的漏洞;其实还可以换个角度,还是每次插入一个串就把 last 设为 $1$ ,但加入一些特判,当 last 已经有这个儿子的时候我们特殊处理,不创建新节点,然后每次返回的下一个字符的 last ,就可以做到在线
1 |
|
时间复杂度分析
直接给出结论:
- 状态数(节点数)为线性 $O(2 \mid T \mid)$
- 转移函数(边数)上界为 $O(\mid T \mid \mid A\mid)$
- 离线时间复杂度为 $O(\mid T \mid \mid A \mid + \mid T \mid)$
- 在线时间复杂度为 $O(\mid T \mid \mid A \mid + G(T))$
不难发现,当给定模式串集的时候,离线和在线时间复杂度一样,实际运行时在线的常数明显更小,且好打,所以建议打在线;而当给定 Trie 的时候,离线的时间复杂度更优秀
例题
这题麻烦的地方在于树上的路径可以拐,发现如果是自上而下的路径我们就可做了,我们发现一个巧妙的性质:
对于无根树树上任意一条路径,一定可以找到一个叶节点使得以这个叶节点为根时,此路径是自上而下的
正确性显然,又看见本题保证叶子个数不超过 $20$ ,直接每个叶子为根都建出 Tire ,然后插到 SAM里面即可
考虑时间,如果我们用在线的办法,由于本题叶子节点只有 $20$ 个, $G(T)$ 其实和 $\mid T \mid$ 是一个级的(当然,如果你愿意,也可以去 dfs $20$ 次把 Trie 建出来)
1 |
|