不只是线段树的那个……
扫描线
普通
虽然线段树那里已经学过一点扫描线了,但还是问一问:
给定一些矩形,求其面积并
这个太简单了,直接跳过了
进阶
看这个:
给定一些三角形,求其面积并
分析
三角形比矩形讨厌的地方在于,矩形平行于坐标轴,只用考虑四个顶点,但三角形可以斜着
考虑把三角形用顶点和交点划分,如图:
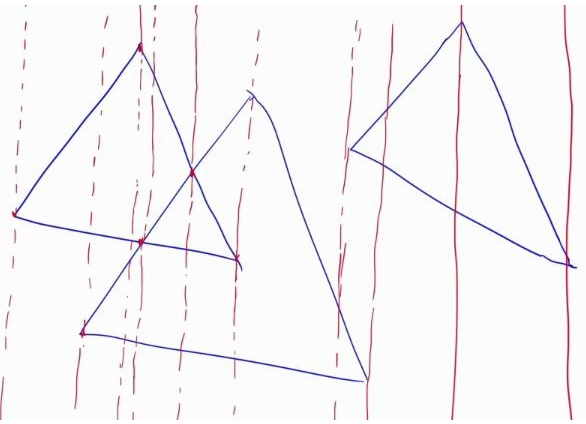
每两个红色的线之间不存在边的交点,换句话说,都是梯形(广义上的),直接两边线段长度求并,乘高除以二即可
由于三角形有 $n$ 个,两两间都可能有交点,故时间复杂度为 $O(N^3)$
注意三角形有边和扫描线重合的特判,排序即可
代码
大量使用 STL 的后果是,不开 O2 TLE 一个点,开了直接飞过去
1 |
|
炼狱
解决了三角形,就相当于解决了所有多边形(剖分成三角性即可),可正当你得意都时候,圆来了
圆咋办?如果扫描线的话那个弧形可不好求,没有办法,为了对付大boss,只好祭出大杀器——自适应辛普森积分
辛普森积分
先看看辛普森积分是神马
顾名思义,这是一种积分方法,来看下面这个函数:

求面积当然是用积分了,但它的解析式又很麻烦,咋办?
辛普森提出一个玄妙的方法:把他近似成一个二次函数
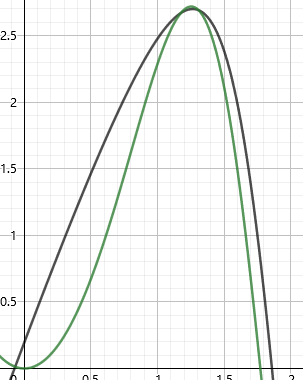
如图,直接把绿色曲线当成黑色的二次函数积分,设绿色曲线为 $y = f(x)$ ,取 $(l, f(l)), (r, f(r)), (mid, f(mid))$ 三个点确定这个黑色的二次函数
二次函数的积分就很好求了,就是:
$$
\frac{f(l) + f(mid) * 4 + f(r)}{6} * (r - l)
$$
自适应
解决了辛普森,来看看自适应
显然直接辛普森积分是无法满足精度要求的,我们要让他“适应”我们设定的精度,具体地,对于区间 $[l, r]$ ,设其辛普森积分后面积为 $S$ ,而区间 $[l, mid], [mid, r]$ 辛普森积分的面积为 $L, R$ ,若 $|L + R - S| < eps$ ,我们就认为这个积分到达了要求的精度;否则,递归积分左右两边,加起来即可
代码
1 |
|
圆的面积并
辛普森积分的应用一般是更改 f 函数:
1 |
|
再看一道题
上面两道是以前做的,码风略差,来看这个:
一看,这个函数没法直接积分(不像模板1可以硬艹),就只有自适应辛普森,好消息是显然 $x \to \infty$ 时函数值趋近于 $0$ ,但一个问题是,何时此函数发散?
结论是: $a < 0$ 时,原函数发散
什么,推倒?小小年纪不学好天天就想着推倒别人!啥,还要看推倒过程!你你你,这在我国是违法的啊!
呃呃,还是给大家 推倒 推导一下
首首先,随便去网上找一个收敛准则:
极限比较判别法 :
对于正项级数 $\{a_n\}, \{b_n\}$ ,有 $\lim_{n \to \infty} \frac{a_n}{b_n} = c$ :
- 若 $c = \infty$ 且 $\sum b_n$ 发散,则 $\sum a_n$ 发散
- 若 $c = 0$ 且 $\sum b_n$ 收敛,则 $\sum a_n$ 收敛
- 若 $c$ 为常数,则 $\sum a_n$ , $\sum b_n$ 同时收敛或发散
然后我们来看这个东西,假设原积分在 $x_0$ 处发散(以下 $\int$ 都不写范围)
$$
\begin{aligned}
& \lim_{x \to x_0} \frac{x^{\frac{a}{x} - x}}{x} \\
= & \lim_{x \to x_0} x^{\frac{a}{x} - x - 1} \\
= & \lim_{x \to x_0} e^{\frac{a}{x} - x - 1 \ln x} \\
= & e^{\lim_{x \to x_0} \frac{a}{x} - x - 1 \ln x} \\
\end{aligned}
$$
显然 $\int x$ 是发散的,我们想让 $\int x^{\frac{a}{x} - x}$ 发散,那么就要上式 $= \infty$ ,而如果 $x \to \infty$ (显然 $x \ge 0$ ),那么无论 $a$ 如何取上式都为 $0$ ;所以为了让上式 $= \infty$ , $x \to 0$ ,此时如果 $a < 0$ 则上式 $= \infty$ ,由极限比较判别法可知, $\int x^{\frac{a}{x} - x}$ 发散
什么?你还想推倒收敛?色胆包天,我我我,我要报警了
开玩笑,下面 推倒 推导 $a \ge 0$ 时必收敛,其实差不多
还是上面的法则:
$$
\begin{aligned}
& \lim_{x \to x_0} \frac{x^{\frac{a}{x} - x}}{\frac{1}{x}} \\
= & e^{\lim_{x \to x_0} \frac{a}{x} - x + 1 \ln x} \\
\end{aligned}
$$
然后就不用我多说了吧?
1 |
|
然后你会想问 $11$ 行是个啥玩意?其实这是一个公式:
$$
\mid \int_a^b f(x)dx - S(a_1, b_1) - S(a_2, b_2) \mid \approx \frac{1}{15} \mid S(a_1, b_1) + S(a_2, b_2) - S(a, b) \mid
$$